4 ноября, 11:40
OpenAI тестирует новые модели ИИ: результаты показывают высокий уровень ошибок


Умные решения — ai
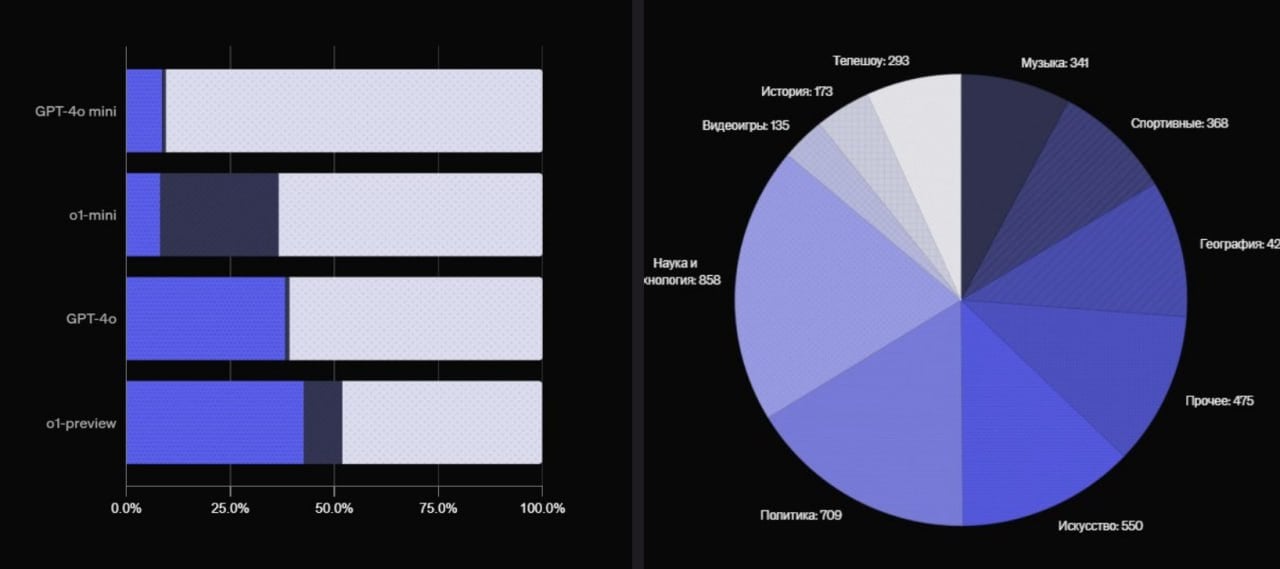
Самая новая и мощная модель ChatGPT, o1-preview, даёт 57% неправильных ответов, — внутренний тест OpenAI. GPT-4o — 60% неверных ответов Claude-3.5-sonnet — 71,1% неверных ответов Как считали? В OpenAI создали тест из 4326 вопросов на темы от кино и науки до географии и технологий. У каждого вопроса строго 1 правильный ответ и модели проверяли на способность точно и уверенно отвечать. это провал
Технологии2 дня назад


Lama News
OpenAI показала, что LLM выдают ложные ответы в 60% случаев. Компания представила бенчмарк SimpleQA для оценки точности выходных данных ИИ. В нём o1 и Claude 3.5 Sonnet продемонстрировали довольно низкие показатели успешности - 42,7% и 28,9% соответственно. Нейронки - это очень крутой инструмент, но пока переставать думать своей головой рано.
Технологии1 день назад


TechnoHub Media
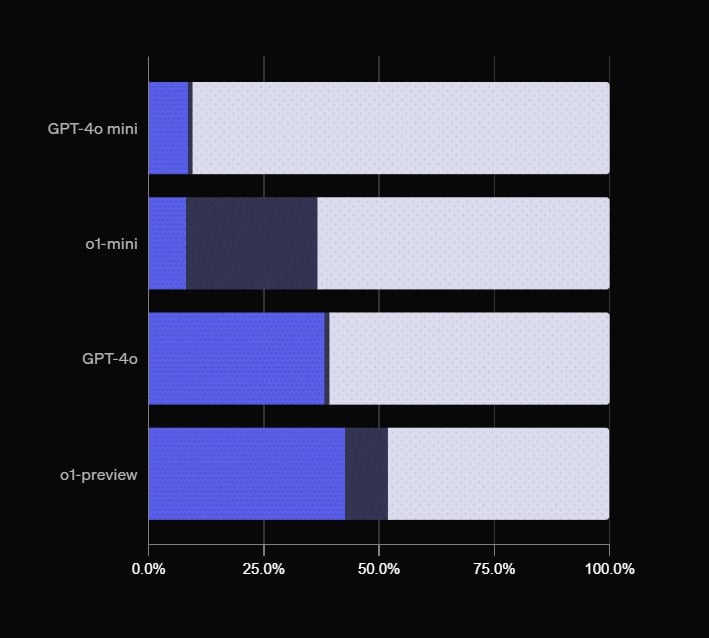
Новый ChatGPT оказался хуже Новая модель o1-preview показала ужасные результаты в тесте от OpenAI. Она ответила правильно только на 43% вопросов. Проверяли с помощью теста, который состоит из 4326 вопросов на темы от кино и науки до географии и технологий. На них ИИ должен был точно и уверенно отвечать. Разница в корректных ответах между GPT-4o и o1-preview составила всего 3%. 2 TechnoHub Media
Технологии2 дня назад

Postium: интернет-медиа
Хьюстон, у нас проблемы! Самая мощная ИИ-модель o1-preview, которая используется в ChatGPT, даёт 57% неправильных ответов, — внутренний тест OpenAI. У модели GPT-4o — 60% неверных ответов. Для проверки ChatGPT дали тест из 4326 вопросов на темы от кино и науки до географии и технологий. Для каждого вопроса только один правильный ответ.
Технологии1 день назад

overbafer1
Новый ChatGPT оказался ТУПЕЕ! Новый ChatGPT - o1-preview от OpenAI, оказался не таким умным, как обещали. Модель с треском провалила тест, правильно ответив только на 43% вопросов. Тест включал 4326 вопросов на темы от кино, истории науки до географии и технологий — так что здесь ИИ реально пришлось бы напрячь мозги, если бы он их имел. Как оказалось в итоге, разница с GPT-4o в подобном тесте, всего 3% — это как замена одного тупого помощника на другого, который знает чуть больше. OpenAI явно ожидали большего, но пока новый ChatGPT никого не впечатлил. А воды стал пить больше.
Технологии1 день назад
Похожие новости






 +1
+1









 +2
+2



 +2
+2
OpenAI представила новую модель ChatGPT o1 для платных подписчиков
Технологии
1 день назад Китайские исследователи разработали военный ИИ-бот ChatBIT на основе модели LLaMA2 от Meta
Технологии
1 день назад +1Религиозные учреждения внедряют ИИ для духовного участия молодежи
Технологии
7 часов назад ChatGPT и Midjourney теперь доступны в Telegram
Технологии
7 часов назад iOS 18.2 beta 2: Новые возможности интеграции с ChatGPT и платная подписка
Технологии
5 часов назад +2Инвестиции в робототехнику: Джефф Безос и другие вложили $400 млн в стартап Physical Intelligence
Технологии
11 часов назад +2